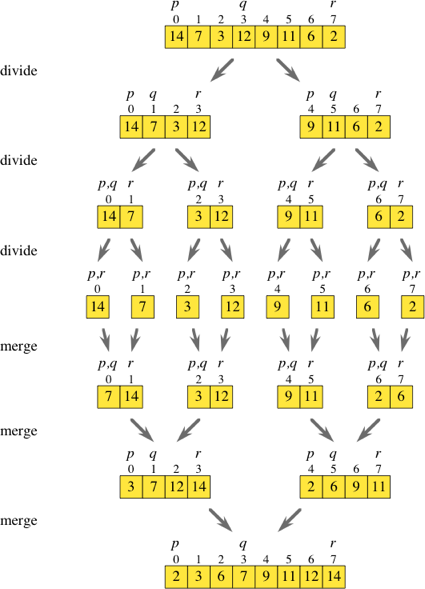
따라서 병합 정렬은 나누기 및 정복 알고리즘입니다. 위의 다이어그램을 보면서 기본적으로 모든 나누기 단계를 무시할 수 있는지 생각했습니다.
2만큼 점프하면서 원래 배열을 반복하면 인덱스 i 및 i + 1에서 요소를 가져 와서 자체 정렬 배열에 넣을 수 있습니다. 이러한 하위 배열을 모두 갖추면 (그림에 표시된대로 [7,14], [3,12], [9,11] 및 [2,6]) 일반 병합 루틴을 계속 진행할 수 있습니다. 정렬 된 배열
배열을 반복하고 필요한 하위 배열을 즉시 생성하는 것이 분할 단계를 전체적으로 수행하는 것보다 덜 효율적입니까?
답변
혼란은 알고리즘 의 개념적인 설명과 그 구현 사이의 차이에서 발생합니다 .
논리적 병합 정렬은 배열을 더 작은 배열로 분할 한 다음 다시 병합하는 것으로 설명됩니다. 그러나 “배열 분할”은 “메모리에 완전히 새로운 배열을 생성”또는 이와 유사한 것을 의미하지는 않습니다. 코드에서 다음과 같이 구현할 수 있습니다.
/*
* Note: array is now split into [0..n) and [n..N)
*/
즉, 실제 작업이 수행되지 않으며 “분할”은 순전히 개념입니다. 그래서 당신이 확실히 제안하는 것은 작동하지만 논리적으로 여전히 배열을 “분할”하고 있습니다-컴퓨터에서 할 일이 필요하지 않습니다 🙂
답변
나는 당신이 의미하는 바는 상향식 구현 이라고 생각한다 . 상향식 구현에서는 단일 셀 요소에서 시작하여 요소를 더 큰 정렬 된 목록 / 배열로 병합하여 위쪽으로 이동합니다. 가운데 배열, 즉 한 요소 배열에서 시작하여 위 그림의 화살표를 뒤집으십시오.
또한 배열이 일정한 크기에 도달 할 때까지 배열을 나눔으로써 병합 정렬 을 최적화 할 수 있습니다 . 그런 다음 삽입 정렬과 같이 단순히 정렬합니다.
그렇지 않으면 배열을 나누지 않고 정렬 할 수 없습니다. 실제로 Merge 정렬의 요점은 하위 배열, 즉 나누기 및 정복을 나누고 정렬하는 것입니다.